
redteam-主动信息收集
本文提供的资料和信息仅供学习交流,不得用于非法用途;
对于因使用本文内容而产生的任何直接或间接损失,博主不承担任何责任;
本文尊重他人的知识产权,如有侵犯您的合法权益,请在vx公众号SecurePulse后台私信联系我们,我们将尽快删除
本文来源:大白哥红队攻防演练课程(Des师傅授课部分)
需要咨询课程详情,请扫下方二维码添加大白哥绿泡泡
一、主动信息收集简介
主动信息收集是通过枚举性模糊探测尝试去寻找目标域名对应的子域名以及开放的端口与服务等;
通过子域名或者IP,对目标资产进行全端口遍历、路径遍历等
在被动信息收集中导出的资产中,会涉及域名对应的端口或者其他解析IP对应的端口,此时可以对子域名或者ip进行全端口扫描,可能会拿到的东西是无法通过浏览器直接访问的(比如:3306数据库服务)或者其他的非WEB协议的端口对应的应用(比如:邮件系统、FTP、服务端搭建的二进制软件应用)
被动信息收集中,通过fofa、hunter等空间搜索引擎进行查询,会因为周期性扫描以及网络波动等问题,有可能导致没有同步目标单位最近的一些情况。虽然主动的信息收集会触发安全设备的告警,但是也能够帮助我们发现一些第三方的测绘平台没有发现的信息,从而扩大攻击面(比如:很少访问的一些站点、新上线的业务)
主动信息收集的核心思路:在被动信息收集中,已经从目标和下级目标获取了足够多的主域名,并以主域名为中心,收集了尽可能多的子域名,接下来可以对他们进行全端口遍历,以及目录路径遍历。
与被动信息收集重合的地方:比如对主域名做子域名收集的时候,在被动信息收集的环节,拿到的子域名都是基于各大接口和DNS解析记录查询获取的,我们还需要通过爆破来获取更多的子域名,以至于能发现更多的子域名以及解析IP。
二、主动信息收集步骤
第1步:子域名爆破,扩大攻击面
被动信息收集时拿到的子域名都是基于各大接口和DNS解析记录查询获取的,不够全面(比如一些测试站点),在主动信息收集中还需要爆破主域名,从而获取更多的子域名。
子域名通常扫3-4级就差不多(往下1-2层)
实战常用
oneforall
可以在api.py文件中配置fofa的key等,增强子域名收集能力
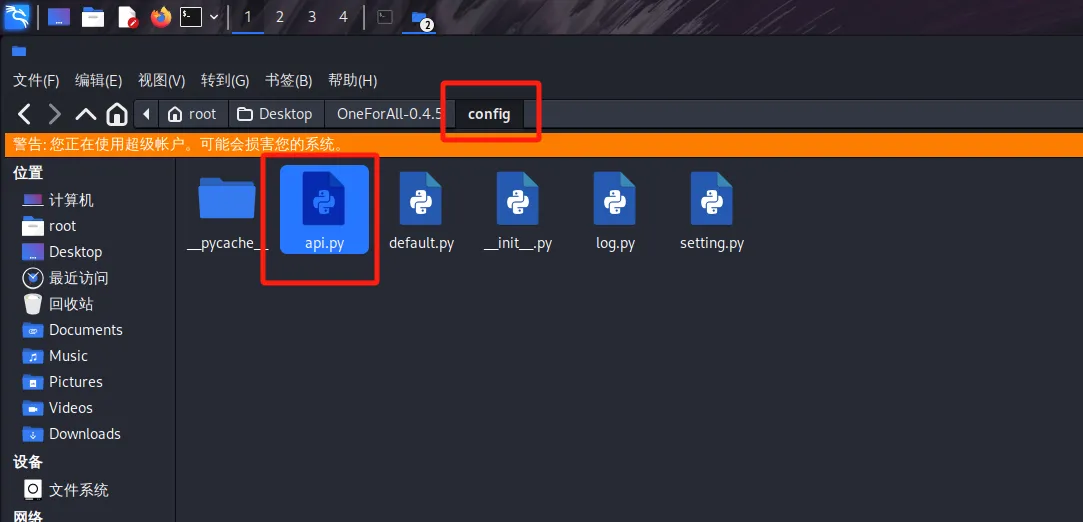
使用命令如下
//多域名扫描
python oneforall.py –-targets 域名列表 run
python oneforall.py --targets xxx.txt run
//单域名扫描
python oneforall.py –-target 单个域名 run
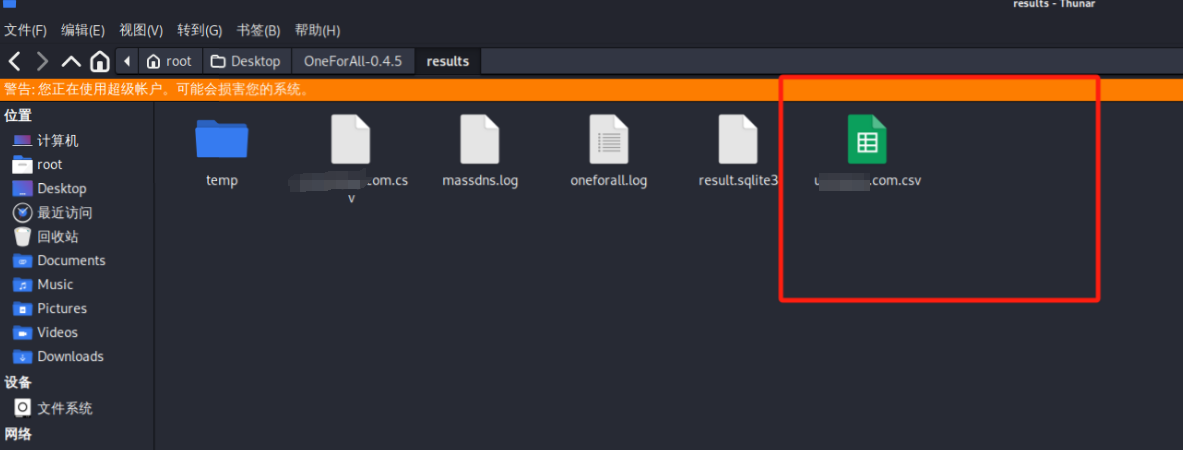
python oneforall.py --target xxx.com run扫描完成后会在oneforall根目录中的results目录生成一个表格文件
subfinder
//批量扫描
subfinder.exe -dL url.txt -o out.txt
//可以配合httpx进行使用,先使用subfinder发现子域名,然后将结果传递给httpx进行遍历
subfinder.exe -dL 根域名列表 | ./httpx.exe -o hackerone.html -html -title
-o hackerone.html 指定输出文件名,将所有子域名的HTML内容保存到hackerone.html文件中。
-html 参数表示保存完整的HTML内容。
-title 参数表示提取并显示页面标题。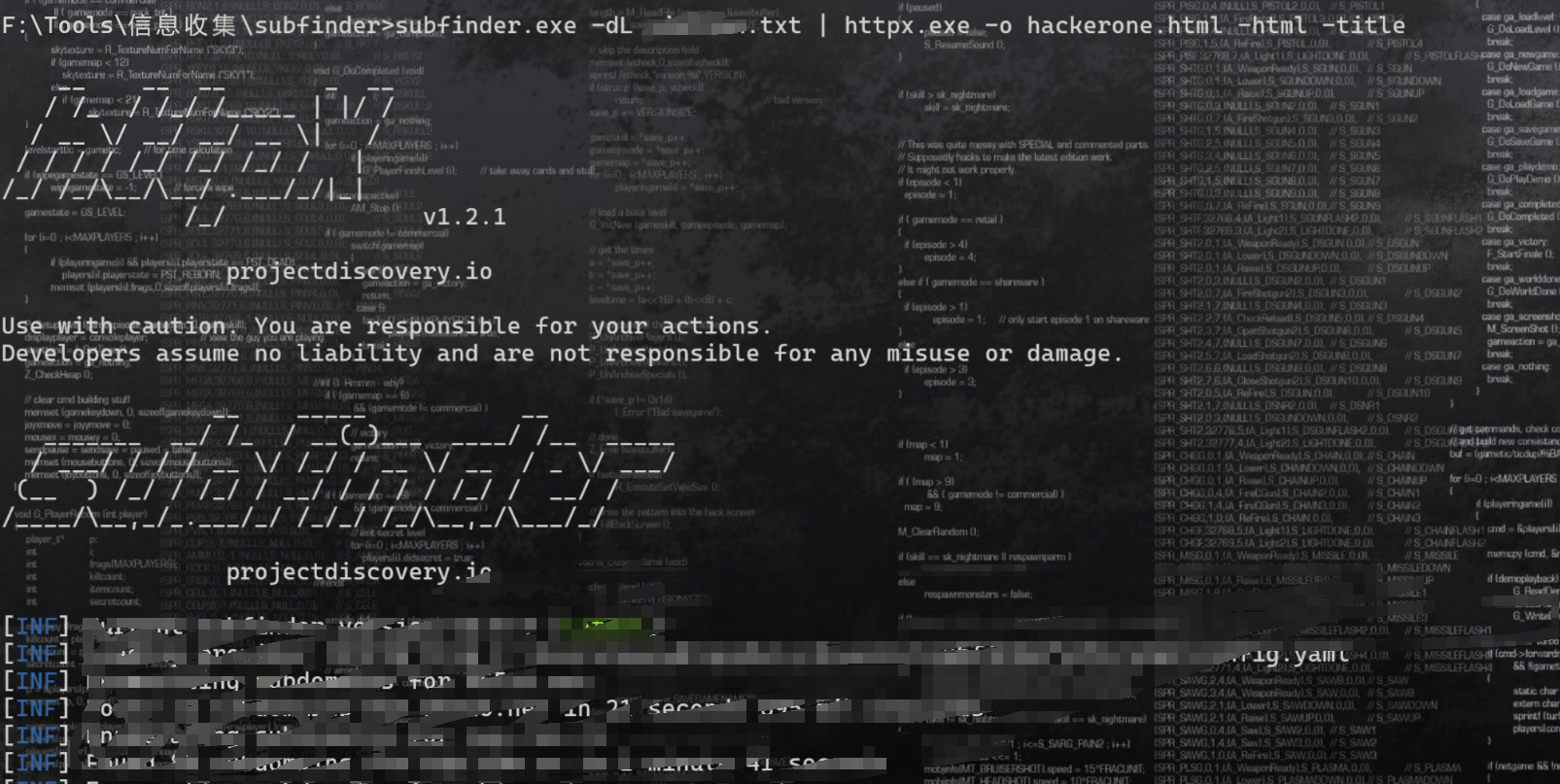
拓展(使用频率较少,用于拓展攻击面)
工具使用-ARL
正式开启漏扫前不要开启漏扫模块,防止封IP
使用原生的ARL扫描子域名效果一般,魔改的ARL内置了oneforall等一些模块,效果不错
原版使用
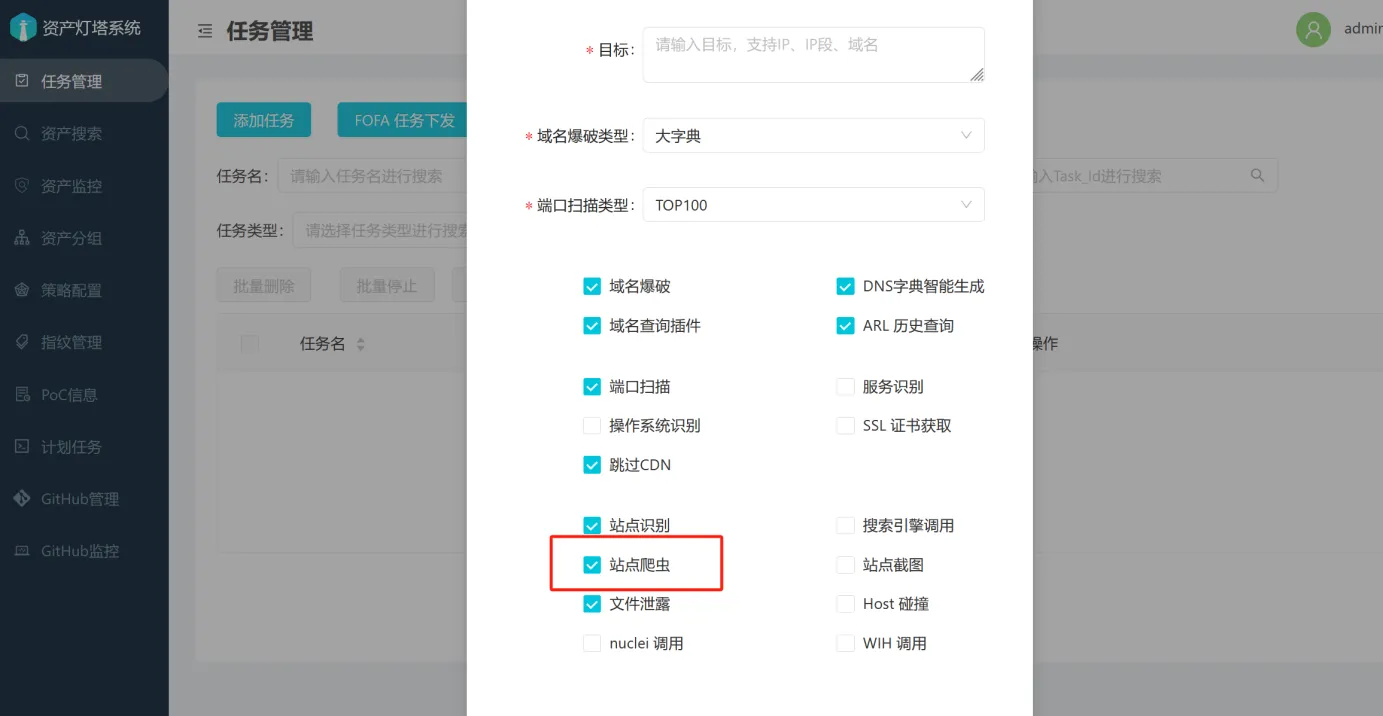
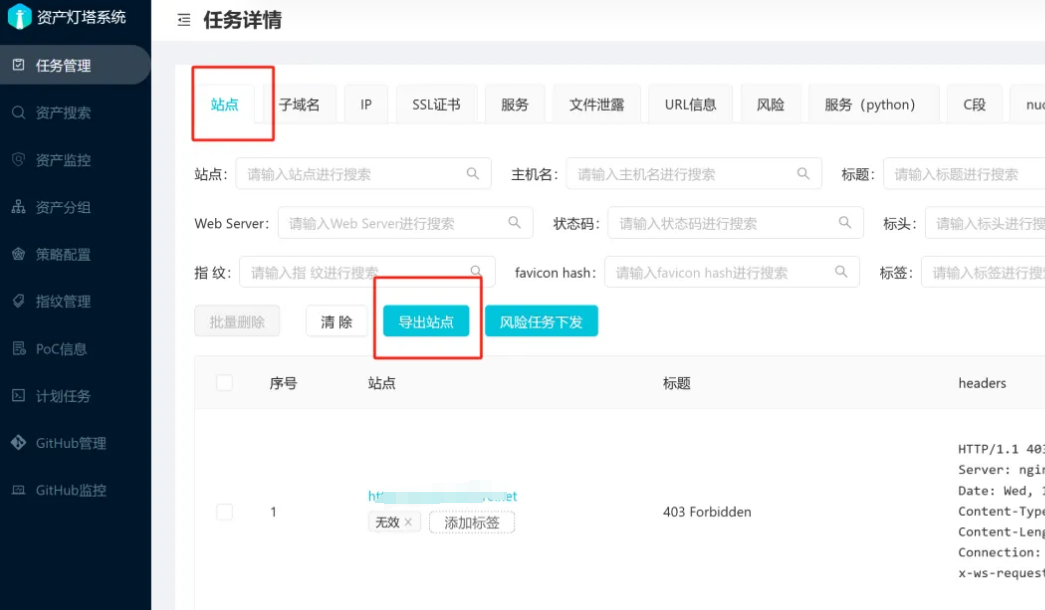
工具使用-EZ
正式开启漏扫前不要开启漏扫模块,防止封IP
使用图形化界面
启动命令
ez.exe web --no-safe-path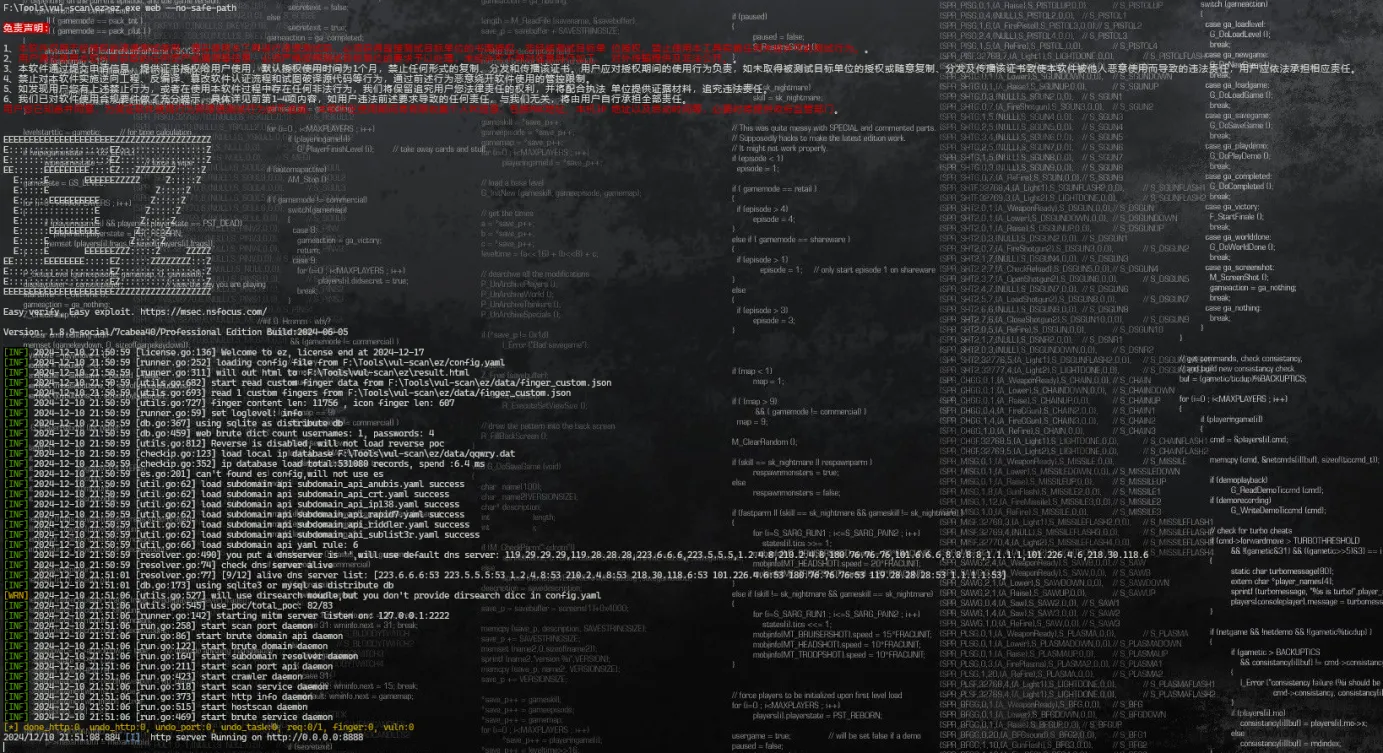
启动成功后访问127.0.0.1:8888进行登录(默认密码为ez)
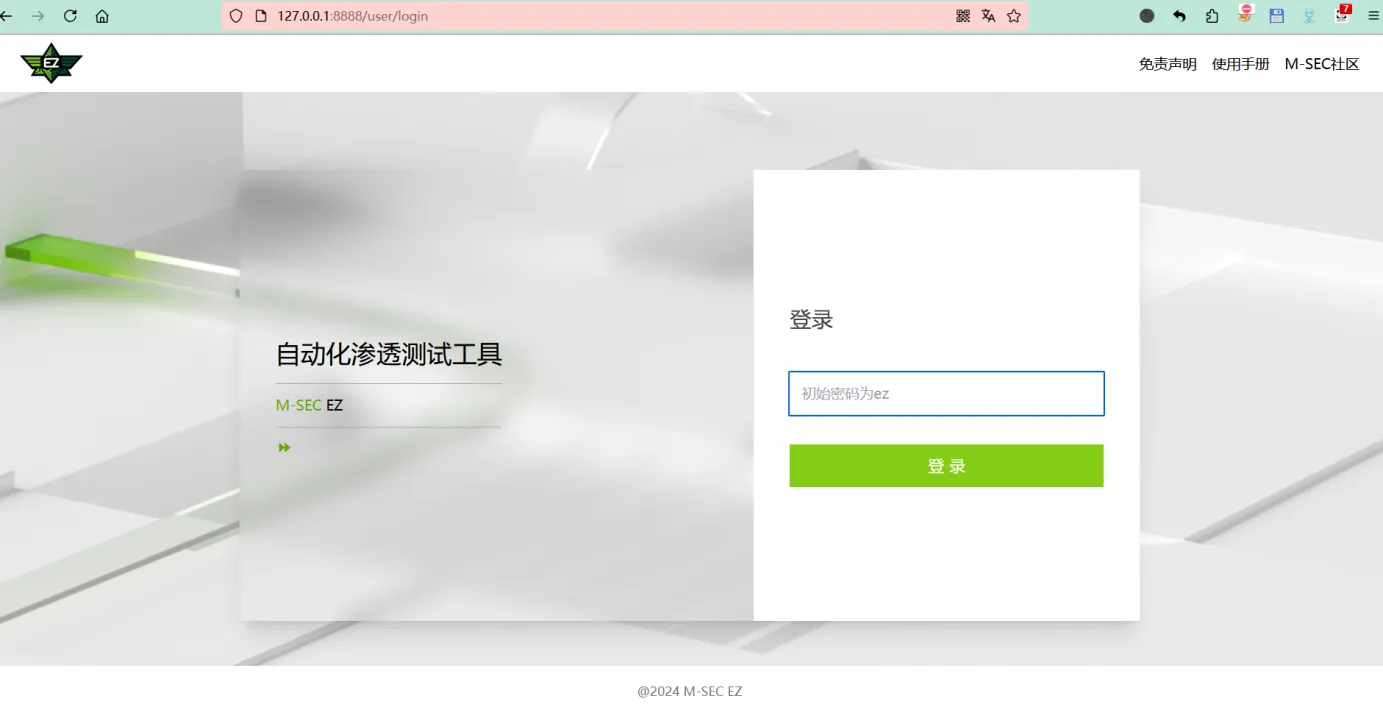
登录后要求修改密码,如果后续登录忘记密码可以使用以下命令重置密码为ez
ez.exe web --reset-web-password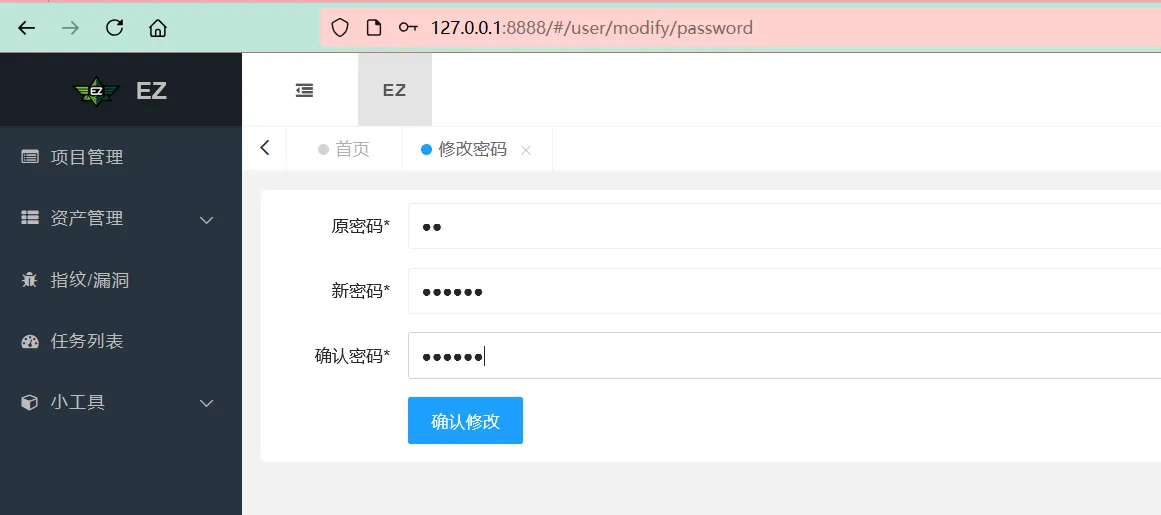
子域名收集
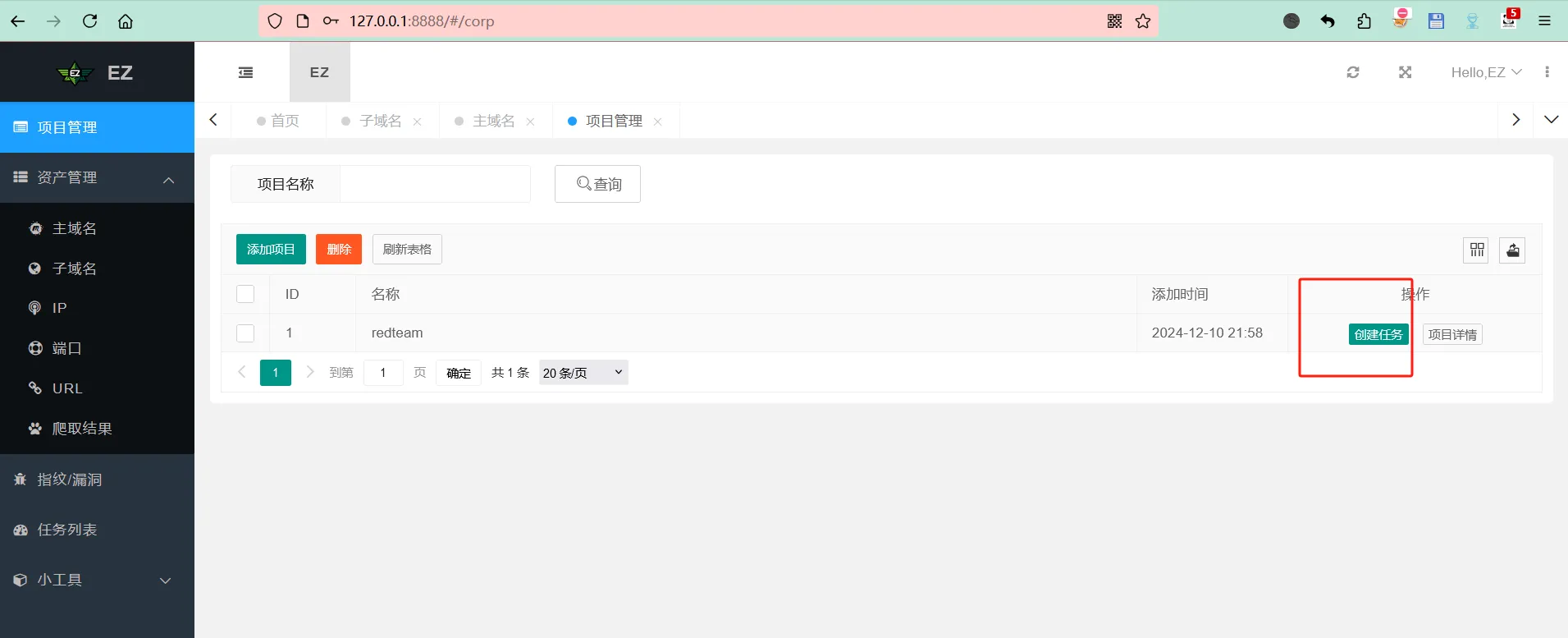
创建项目,将收集的主域名放进去
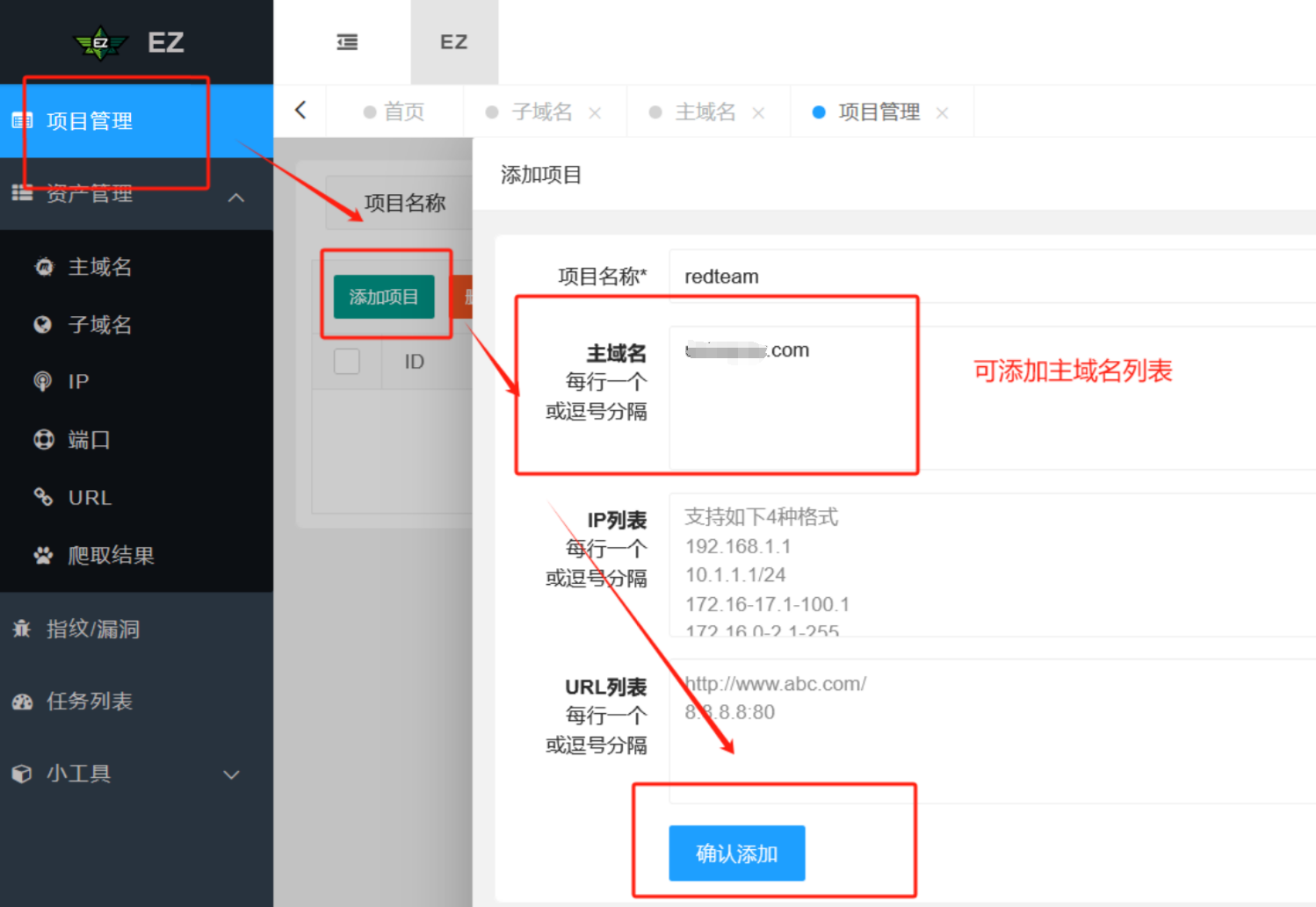
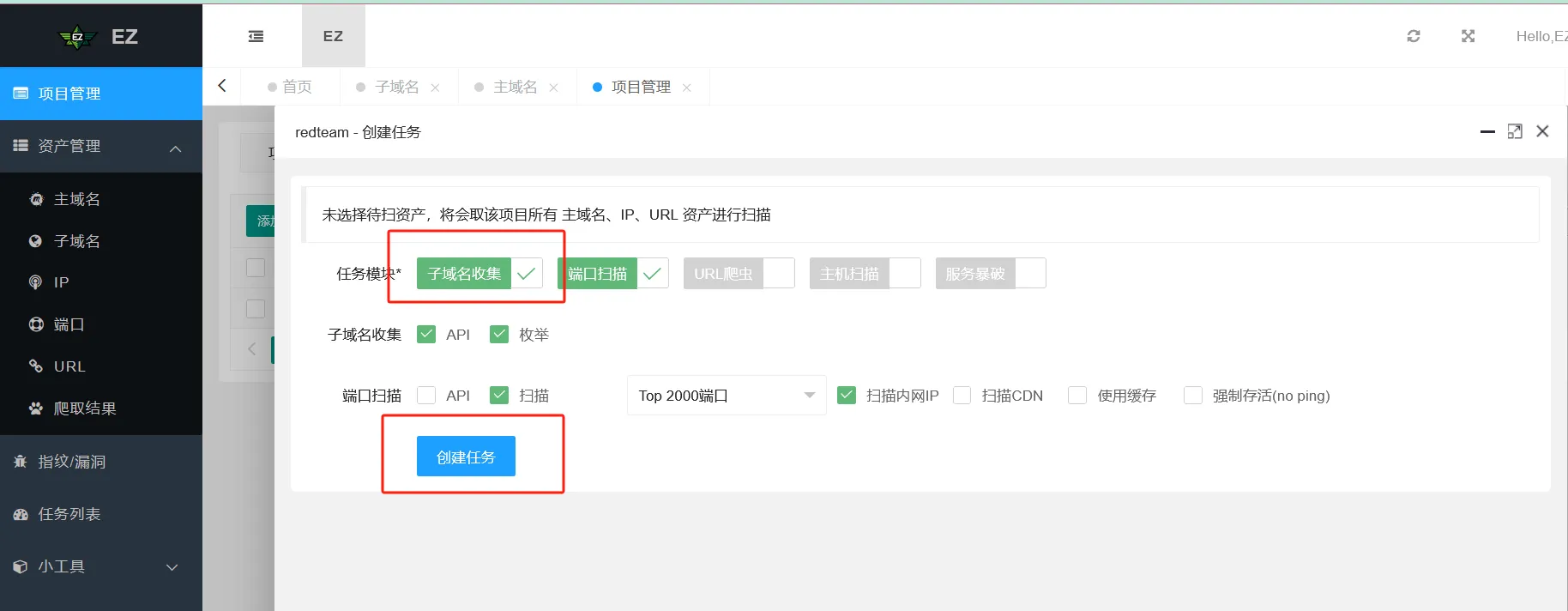
在已创建的项目中创建任务,选择子域名收集
查看收集结果(选择对应的项目)
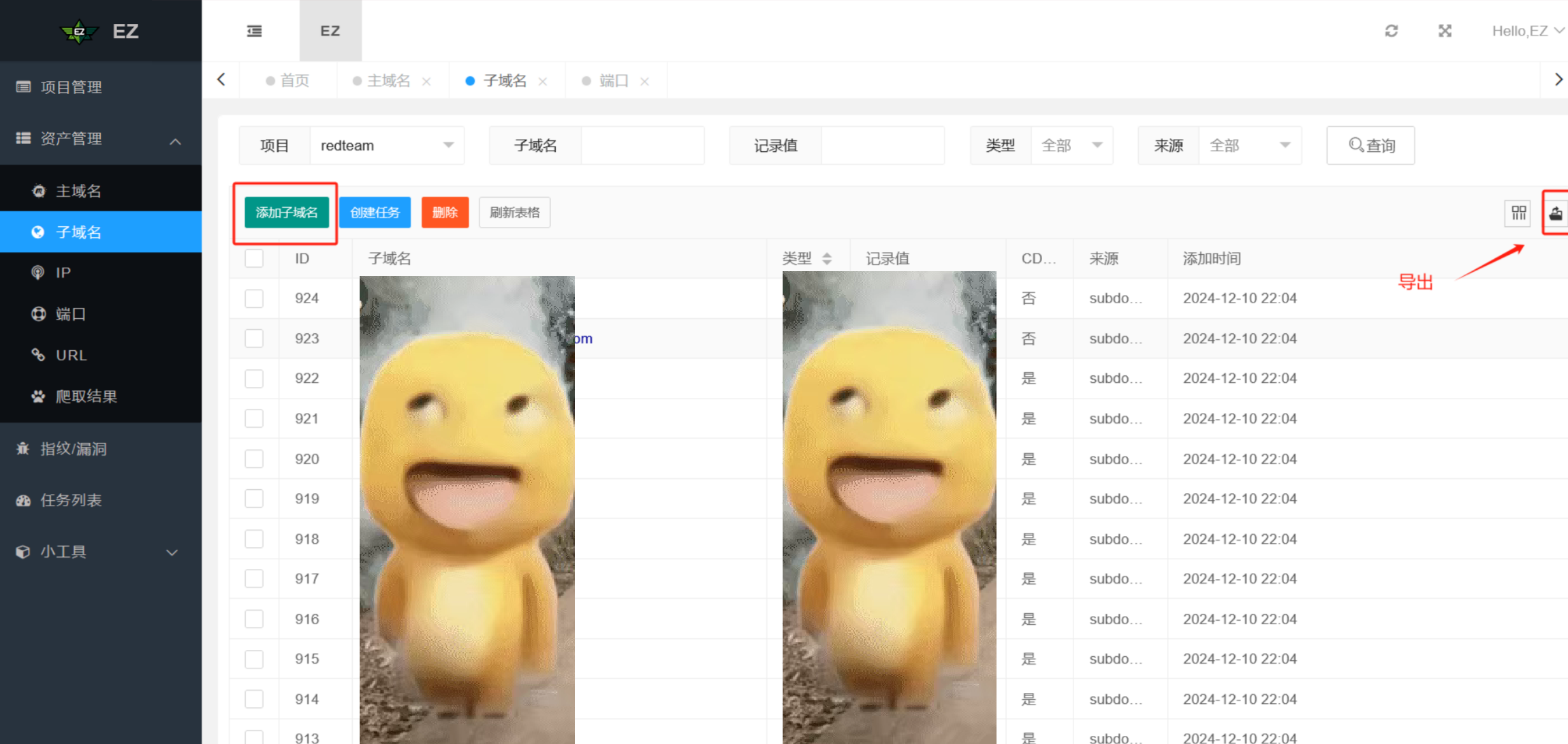
tip:可以将其它方式收集到的子域名添加进结果中,ez会自动去重,然后再导出结果
ez的去重功能比较好用,后续的收集的端口、URL等信息都可以使用ez进行去重
工具使用-Goby
需要安装插件
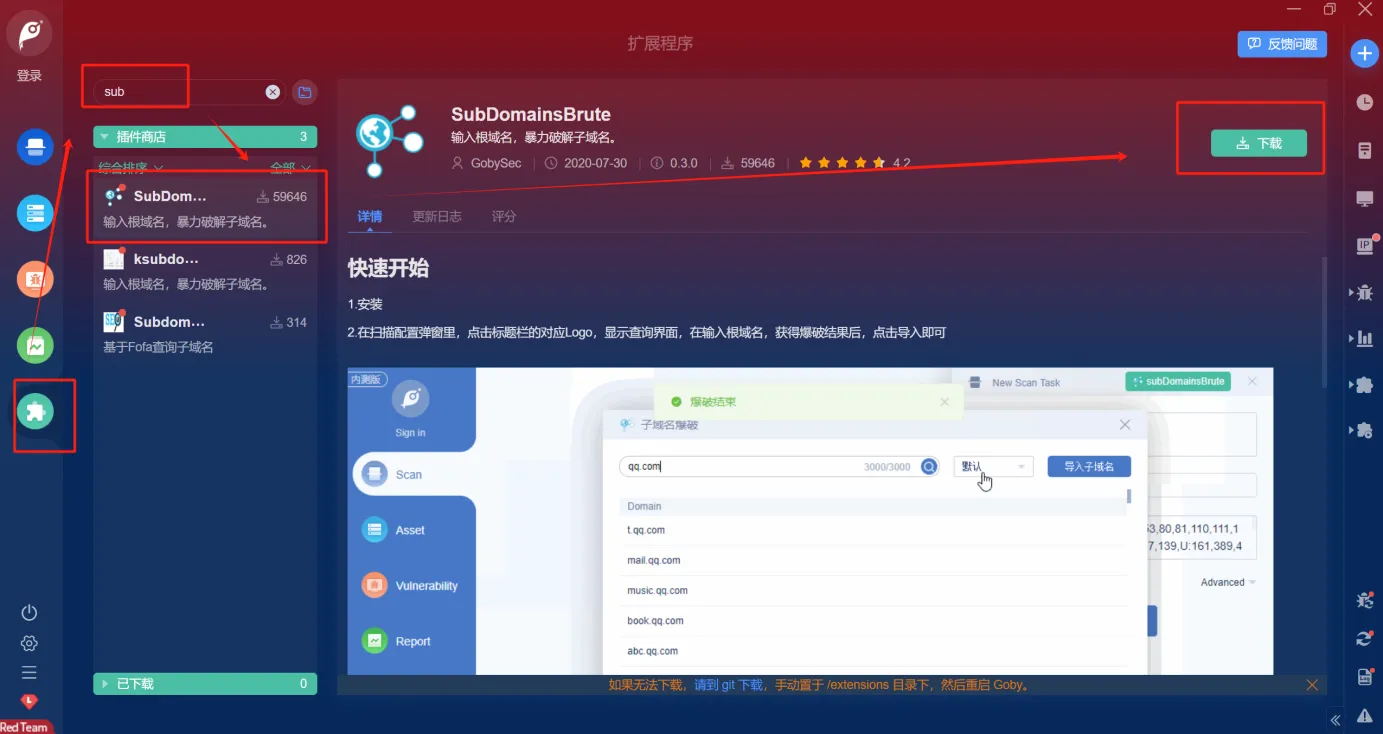
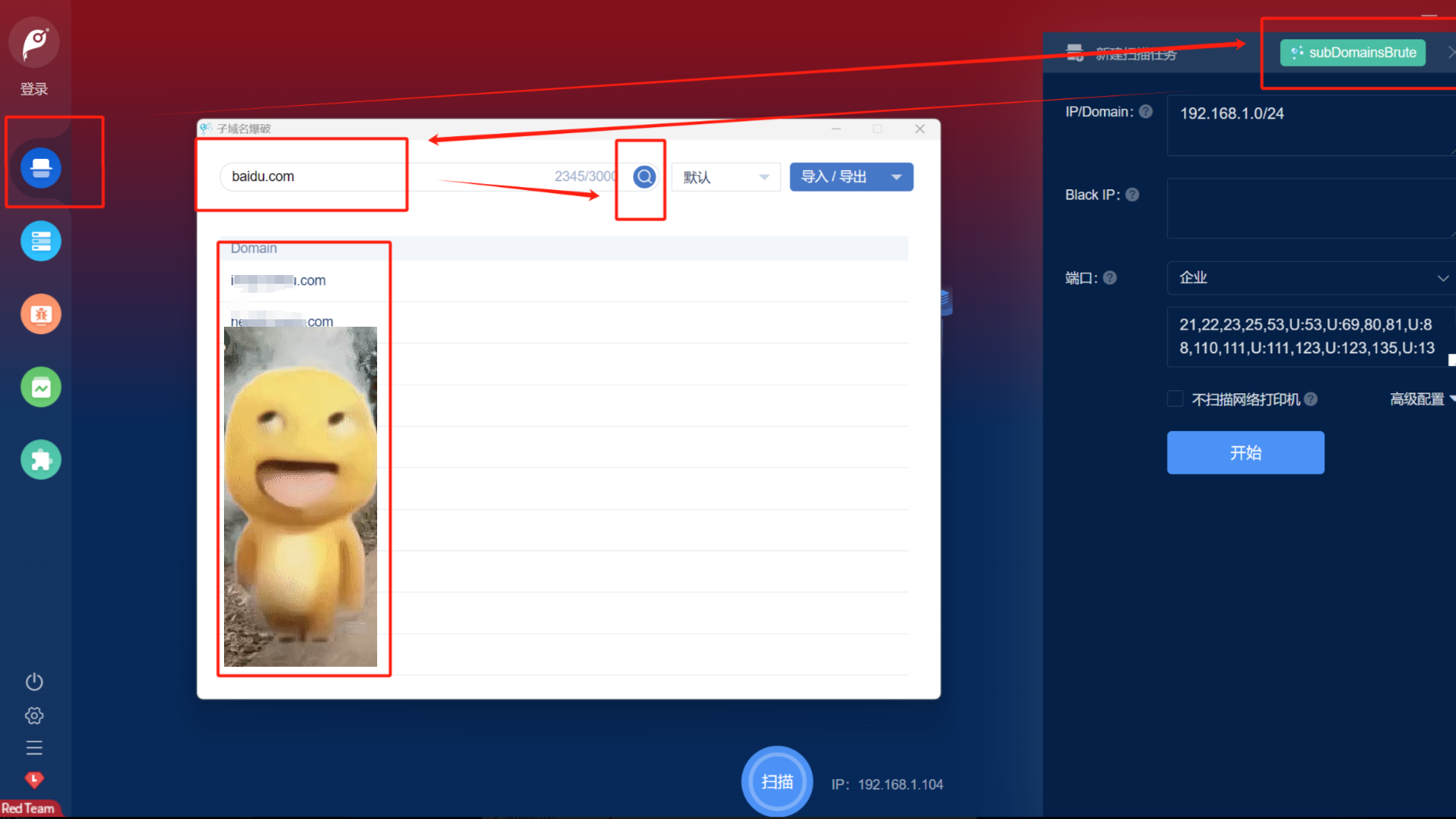
使用方式
layer子域名挖掘机
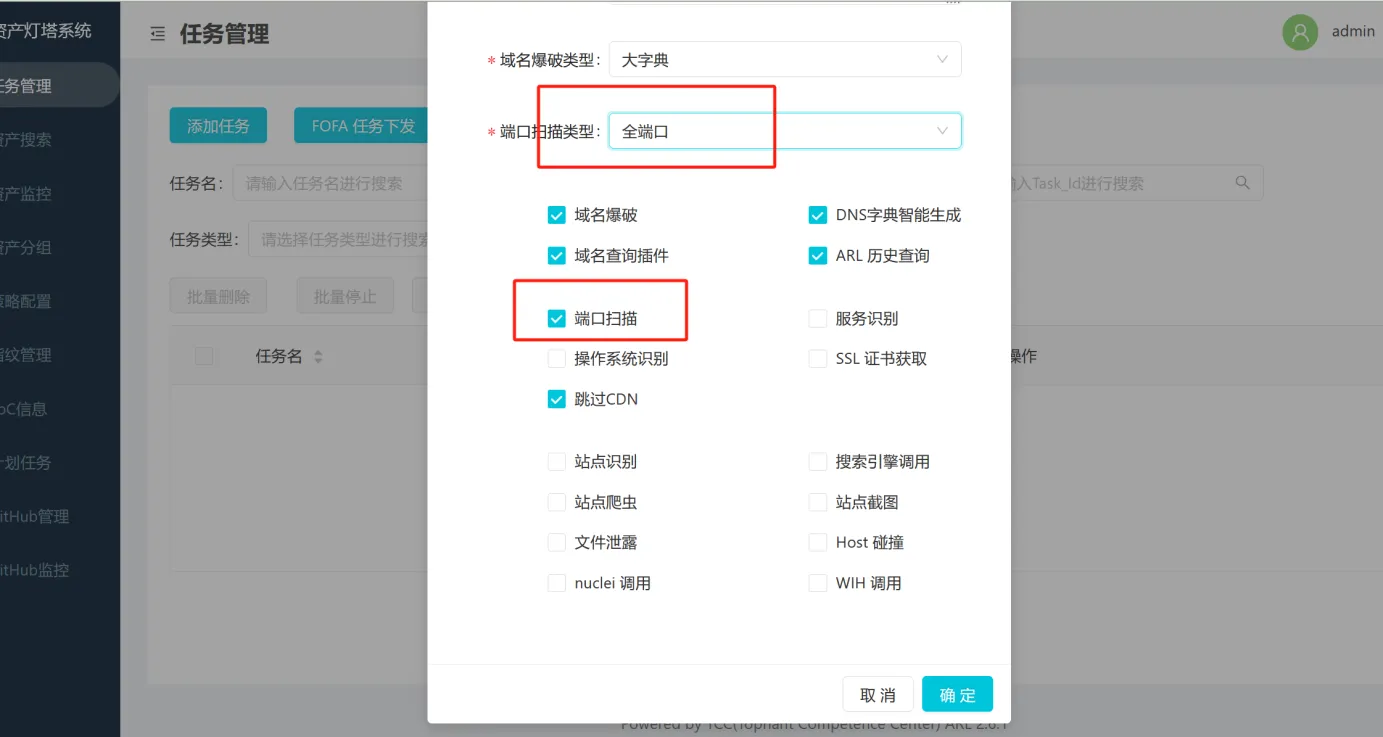
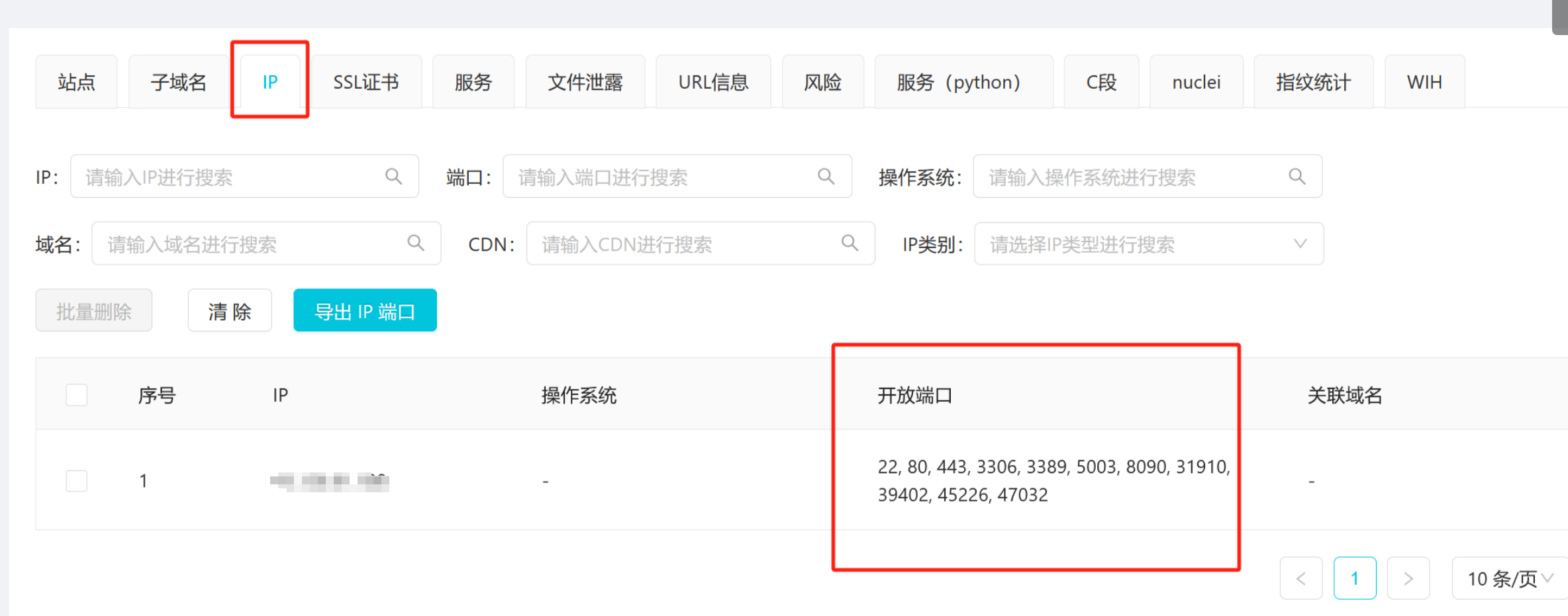
第2步:对收集的资产进行全端口扫描
在红队真实攻防中一般会通过FOFA\Hunter等资产测绘平台先通过主域名、解析IP去批量拿URL和对应的端口服务进行批量化渗透打点,再通过主动信息收集中的top1000和全端口(ARL的top1000端口Masscan的全端口)去扩大信息收集面。
将被动/主动信息收集到的域名/IP进行全端口扫描,在excel表格中做好记录(得到domain:port或者ip:port的映射关系)
单个站IP推荐使用Nmap(慢,但是准确),集群资产推荐使用Masscan(快,但是会有遗漏);通常情况下会使用多款工具同时测试(ARL+EZ+Masscan等,然后将扫描的结果全部同步到EZ,最后一起导出来)
常见端口介绍
TCP 20、21(FTP默认端口)
利用点:允许匿名的上传下载、爆破、嗅探、win提权、远程执行(proftpd 1.3.5)、各类后门(proftpd,vsftp 2.3.4)
TCP 22(SSH默认端口)
利用点:可根据已搜集到的信息尝试爆破,v1 版本可中间人,ssh隧道及内网代理转发,文件传输等
TCP 23(Telnet默认端口)
利用点:爆破,嗅探,一般常用于路由器交换机登陆,可尝试弱口令
TCP/UDP 53(DNS默认端口)
利用点:允许区域传送,dns劫持,缓存投毒,欺骗以及各种基于dns隧道的远控
TCP 80-89, 443, 8440-8450, 8080-8089(各种常用的Web服务端口)
利用点:可尝试经典的topn,vpn,owa,webmail,目标oa,各类Java控制台,各类服务器Web管理面板,各类Web中间件漏洞利用,各类Web框架漏洞利用等等
TCP 137,139,445(Samba服务)
利用点:可尝试爆破以及smb自身的各种远程执行类漏洞利用, 如:ms08-067,ms17-010,嗅探等
TCP 135(OXID Resolver)
利用点:在网络安全领域,OXID Resolver被用于远程枚举网络接口,而无需任何身份验证。这意味着,只要目标机器的135端口开放,就可以通过OXID Resolver获取目标主机的网络接口信息,包括网卡地址。这种能力在内网渗透中尤其有用,因为它可以帮助发现多网卡主机,这些主机可能连接到不同的网络区域,从而成为潜在的跳转点
工具使用-webfinder
该工具会把http和https都尝试一遍,一定程度能够避免400这种状态码
可以将子域名和解析IP都用该工具跑
使用方法(需要JDK.18)
//如果双击无法启动可以使用以下命令
java -jar webfinder-next.jar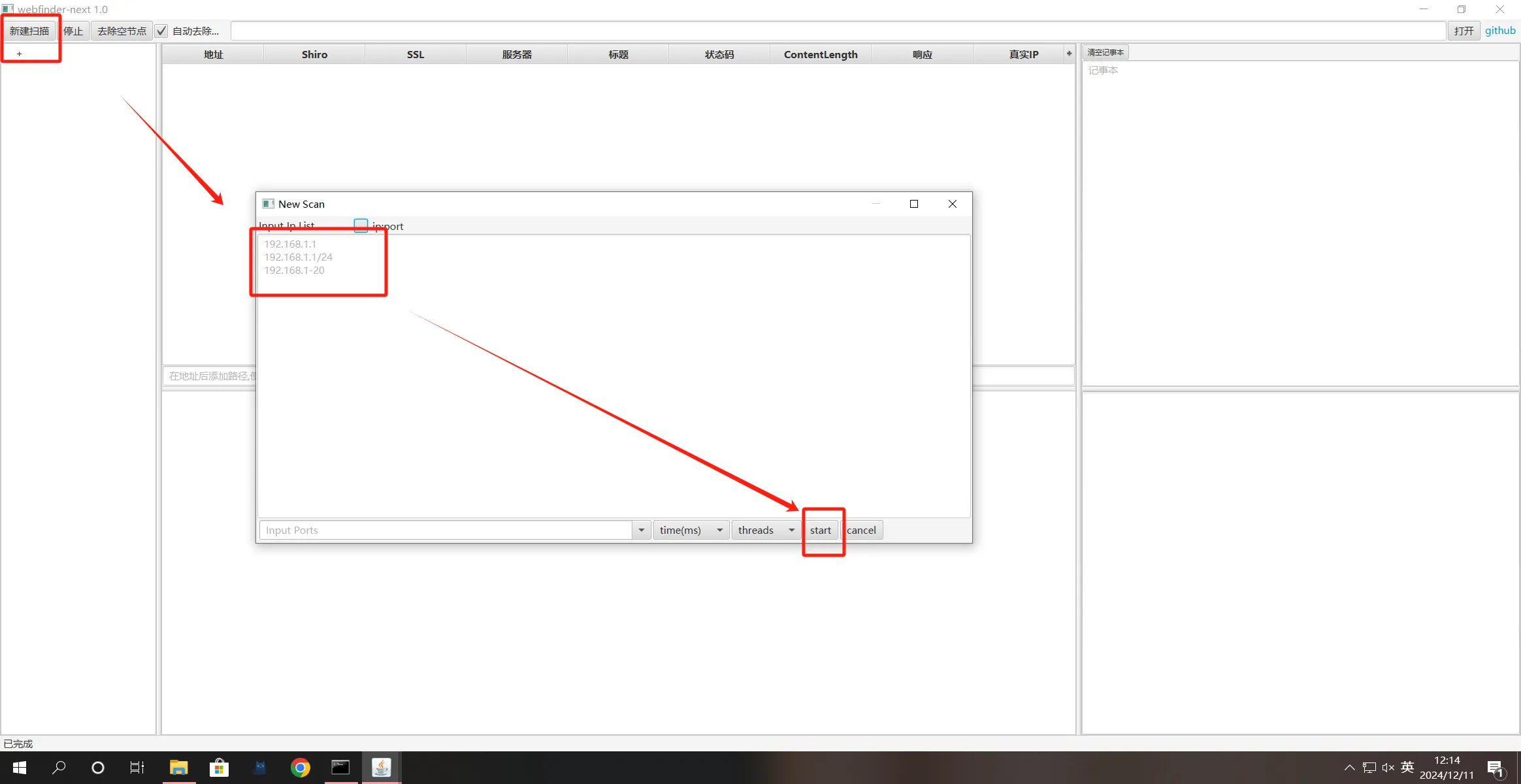
工具使用-Masscan(kali自带)
一般拿到解析IP后用该工具跑一遍
使用方法
masscan 192.168.1.171/24 -p 1-65535
masscan -iL ip.txt -p 1-65535 -oL masscan.txt --rate 2000
-iL ip.txt: 指定包含目标IP地址列表的文件 ip.txt。
-p 1-65535: 扫描所有可能的TCP端口(从1到65535)。
-oL masscan.txt: 将扫描结果以文本格式输出到masscan.txt文件。
--rate 2000: 设置发送SYN数据包的速率,每秒2000个包。。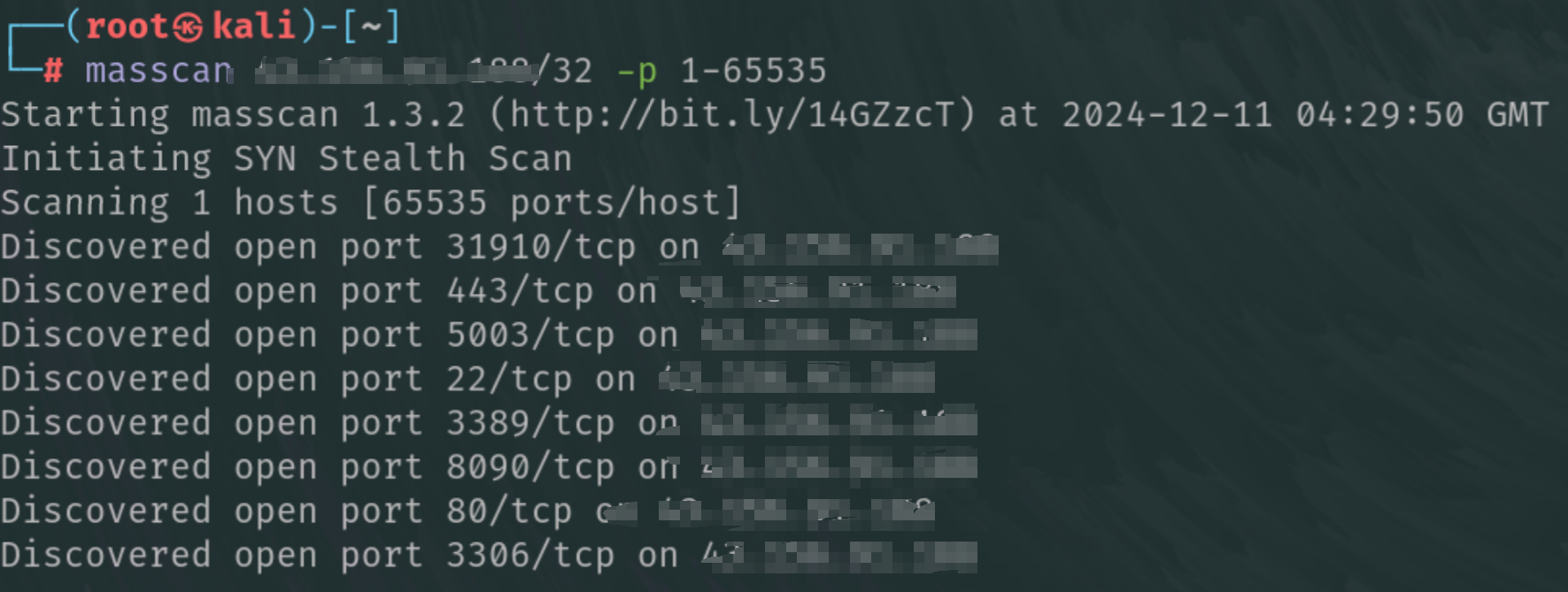
工具使用-ARL
工具使用-EZ
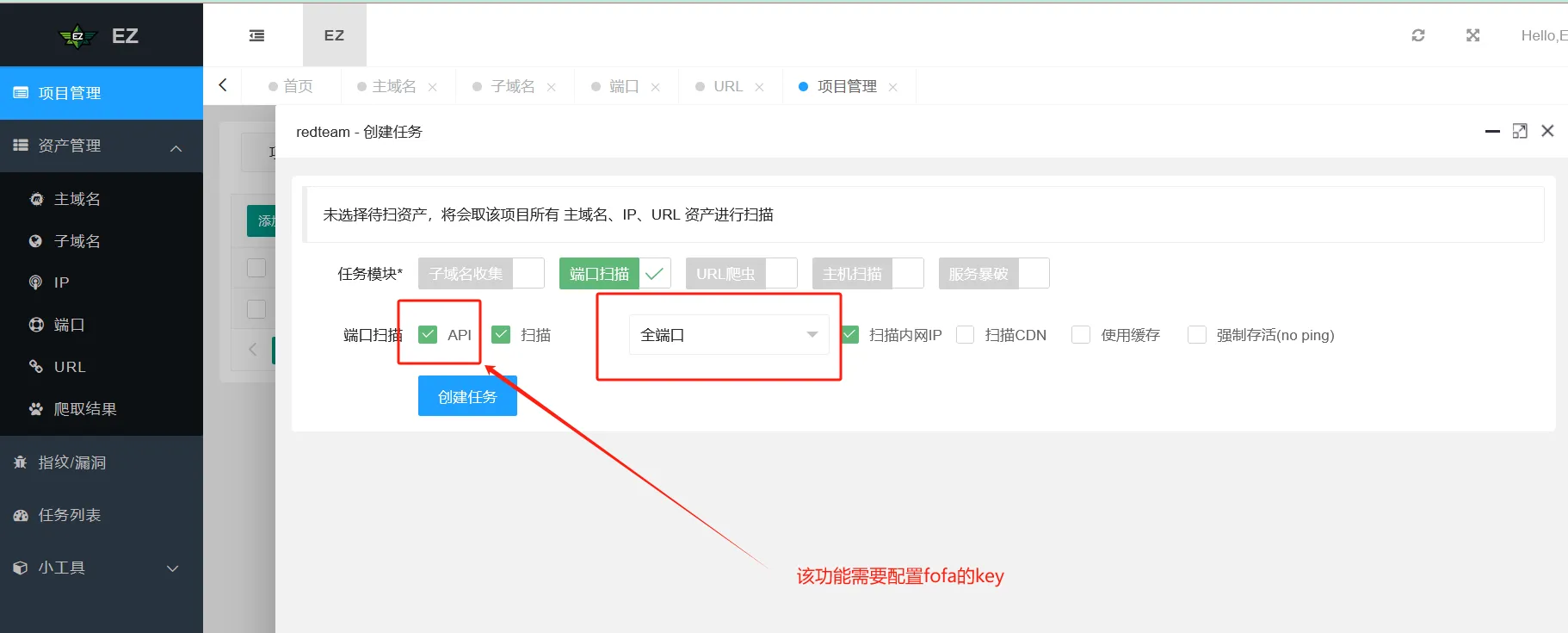
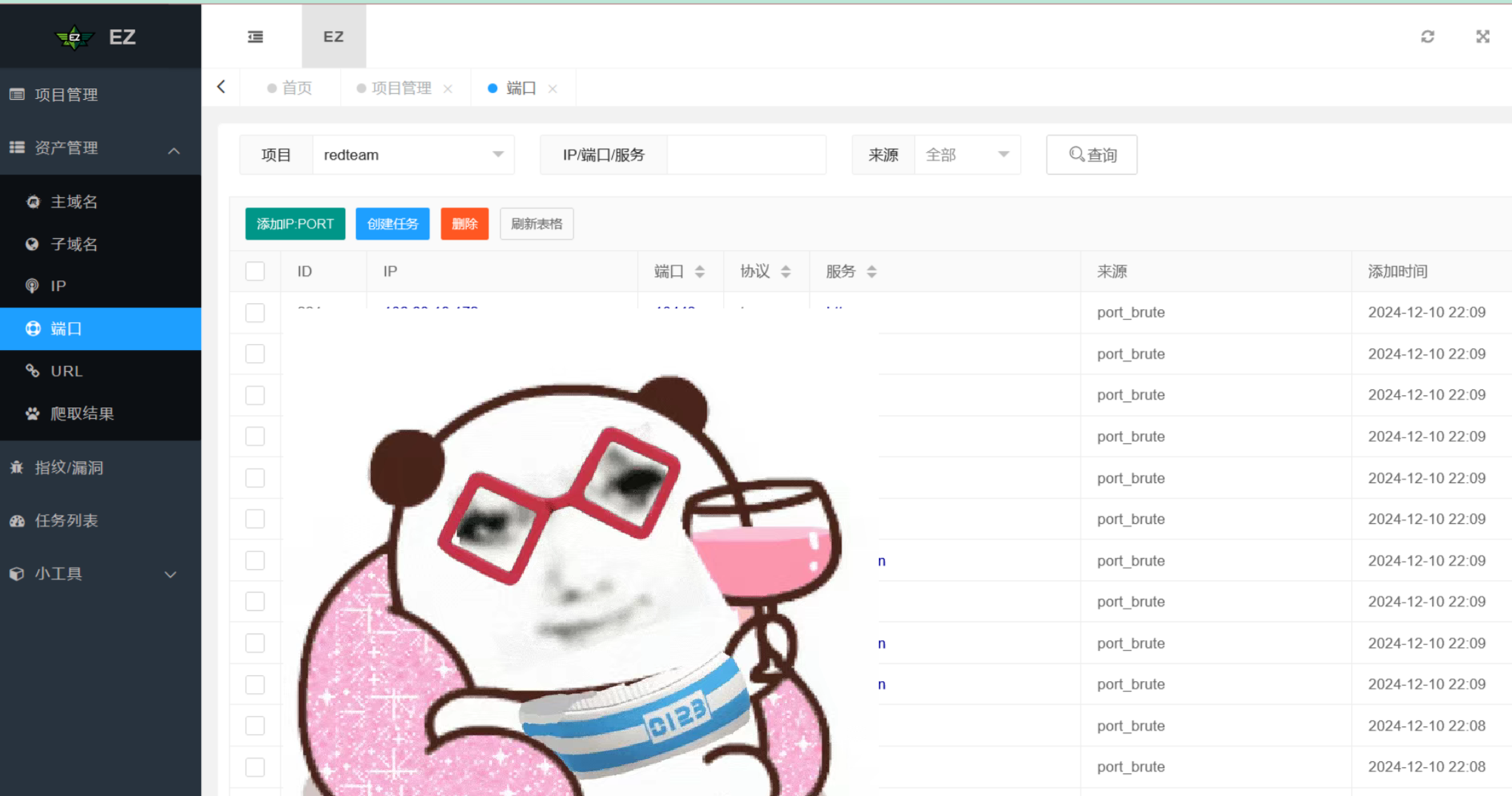
工具使用-Nmap
使用方式:自己查
tips:Nmap效率较低,一般用于精准打击或者HW溯源等场景;在HW反向扫描(高级蓝队溯源工作)中通常都是IP直接丢进ARL\EZ,有资产再去挖掘漏洞进行突破。
第3步:对ip:port、domain:port格式的资产用进行探活
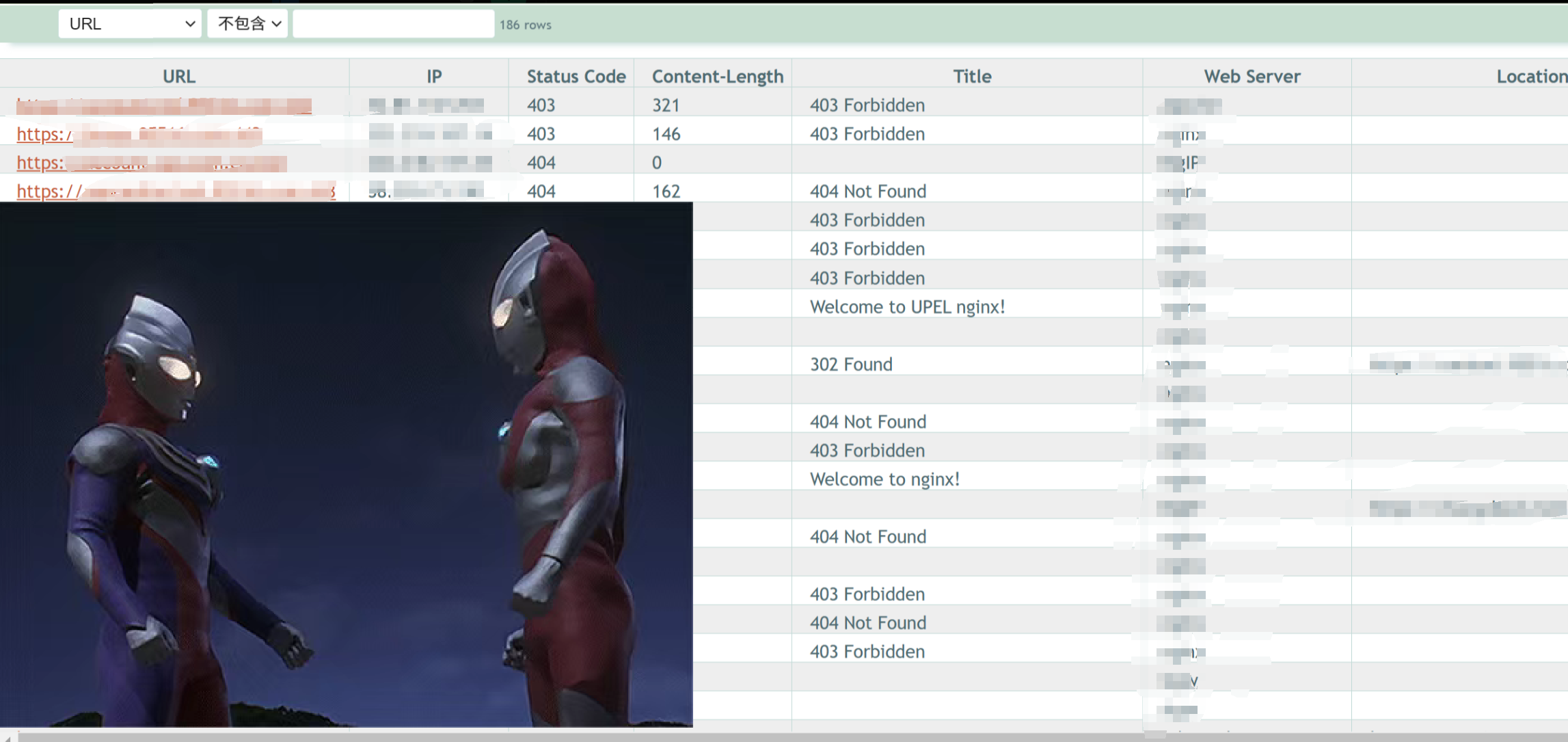
可以用HTTPX工具进行存活验证,并生成URL,因为HTTP不属于漏洞利用,被封IP的概率相对较低
将ip:port、domain:port格式的资产用EZ、ARL进行URL探测(关闭漏扫功能,防止在信息收集阶段就被封IP) 服务识别,获取URL以及端口指纹信息
使用EZ对IP、子域名做一轮top2000端口的扫描,并生成URL、端口指纹信息
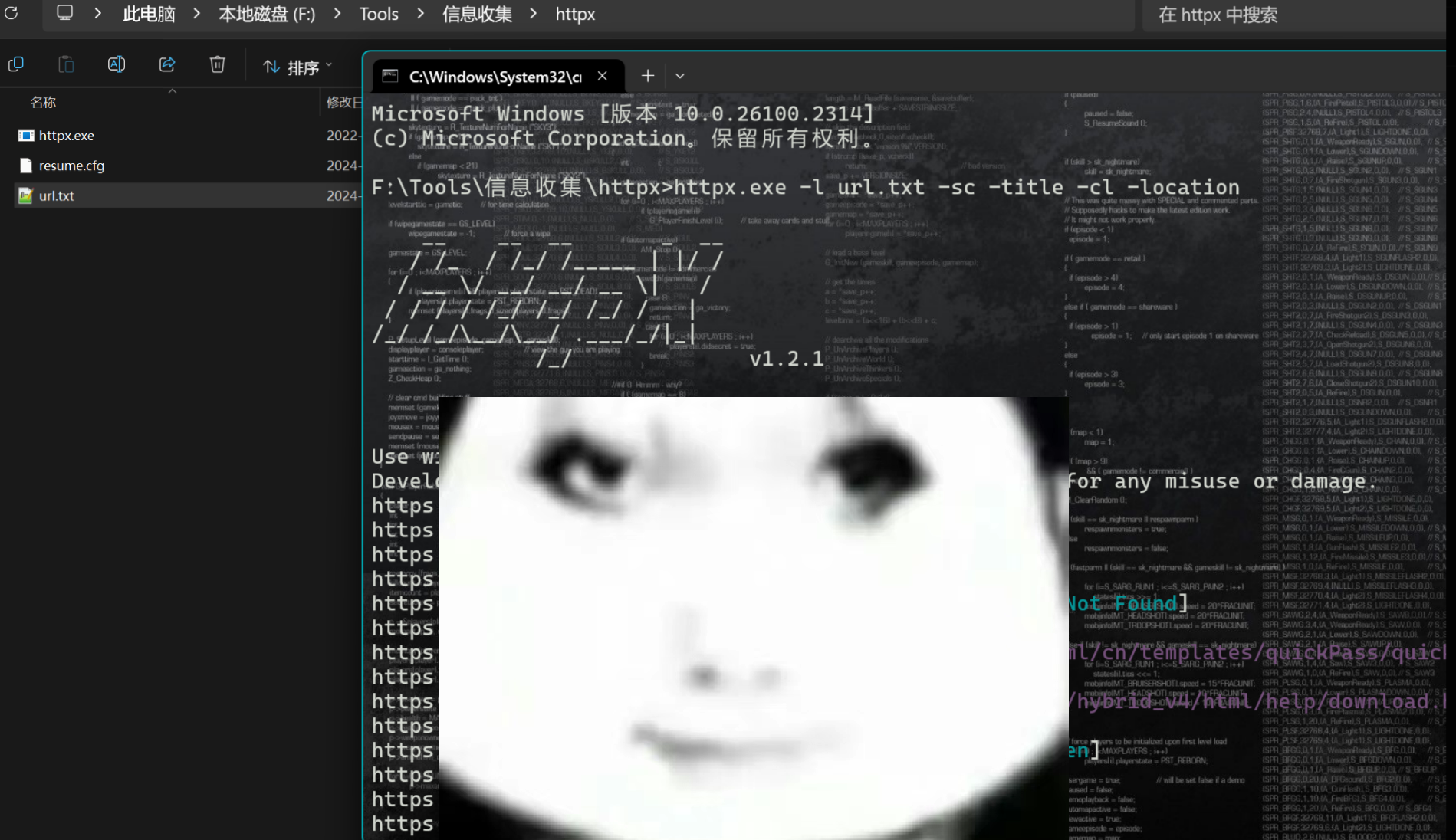
工具使用-HTTPX
httpx.exe -l subdomain.txt -sc -title -cl -location
-l subdomain.txt: 指定包含目标子域名的文件subdomain.txt。
-sc: 获取并显示每个URL的HTTP状态码。
-title: 提取并显示网页的 <title> 标签中的文本,即网页标题。
-cl: 获取并显示网页的内容长度(Content-Length),即响应体的大小(以字节为单位)。
-location: 如果存在HTTP重定向,则获取并显示最终的重定向URL。
httpx -l url.txt -p http:8092,60000,5550,8083,8086,8081,8087,8084,8082,8080,8085,8100,8089,8090,9010,9090,3000,8161,15672,9200,6900,9999,9000,8088,8042,8181,7071,7074,9081,2375,8888,9099,8001,8180,9100,8010,443,80,21,22,81,135,139,445,1433,3306,5432,6379,7001,8000,11211,27017,1510,1511,1512,1614,1715,1879,1880,1910,1911,1912,3690,8911,9699,9701,19001,19002,19003,19004,19005,19704,19705,19706,19707,19708,19709,19710,19711,19712,19714,19715,19716,19717,19718,19719,19720,19721,19724,19725,20001,47373,51439,55906,59208,59482,8899,36933 -path dir.txt -sc -title -cl -location
-path dir.txt: 指定一个文件 dir.txt
该文件中每一行包含一个路径,httpx 将尝试访问这些路径。
例如,如果 dir.txt 包含 /admin, /login, /api/v1/ 等路径,httpx 将会尝试访问 http://example.com/admin, http://example.com/login, http://example.com/api/v1/ 等。
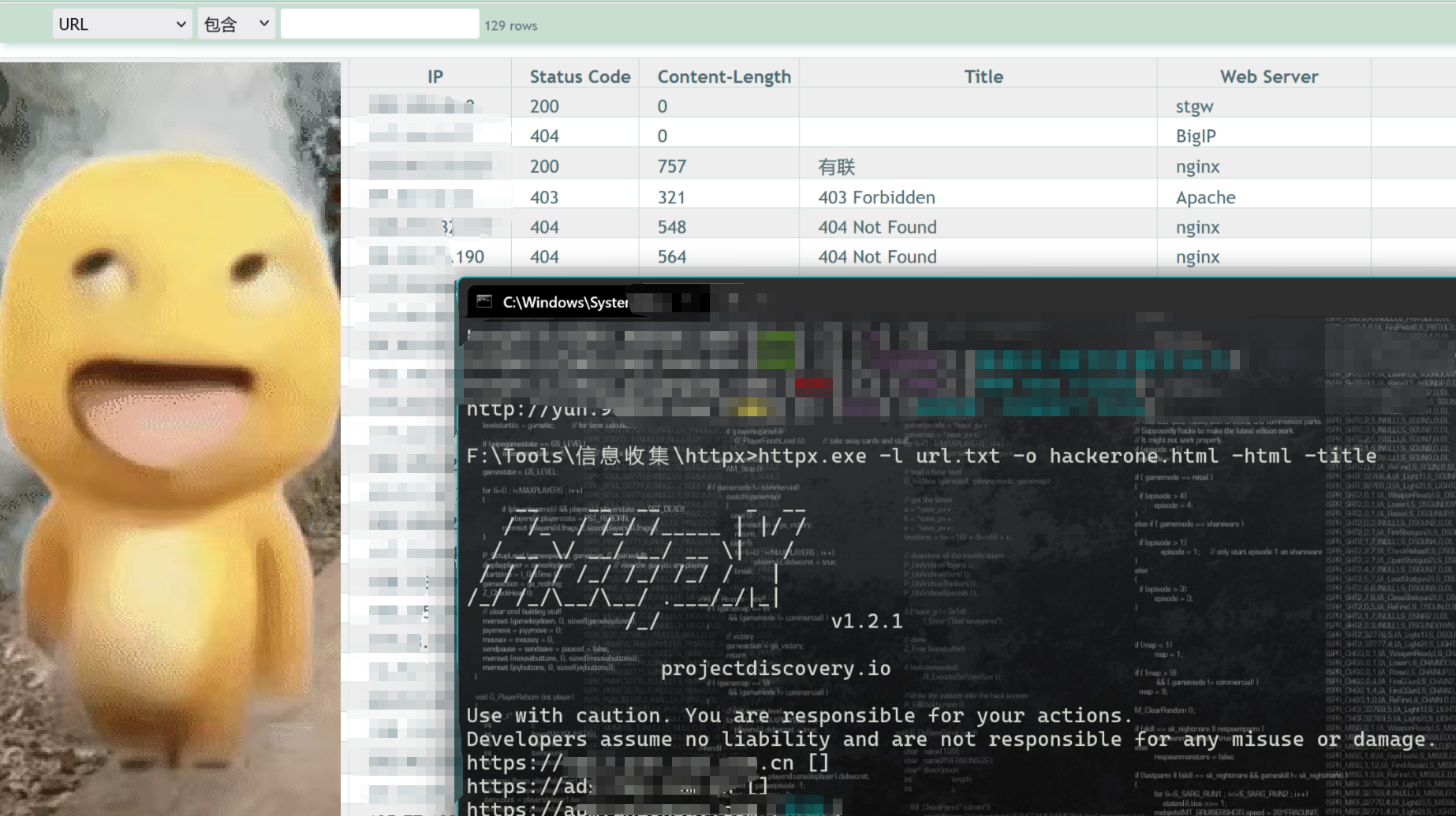
httpx.exe -l url.txt -o hackerone.html -html -title
-o hackerone.html 指定输出文件名,将所有子域名的HTML内容保存到hackerone.html文件中。
-html 参数表示保存完整的HTML内容。
-title 参数表示提取并显示页面标题。
工具使用-ARL
工具使用-EZ
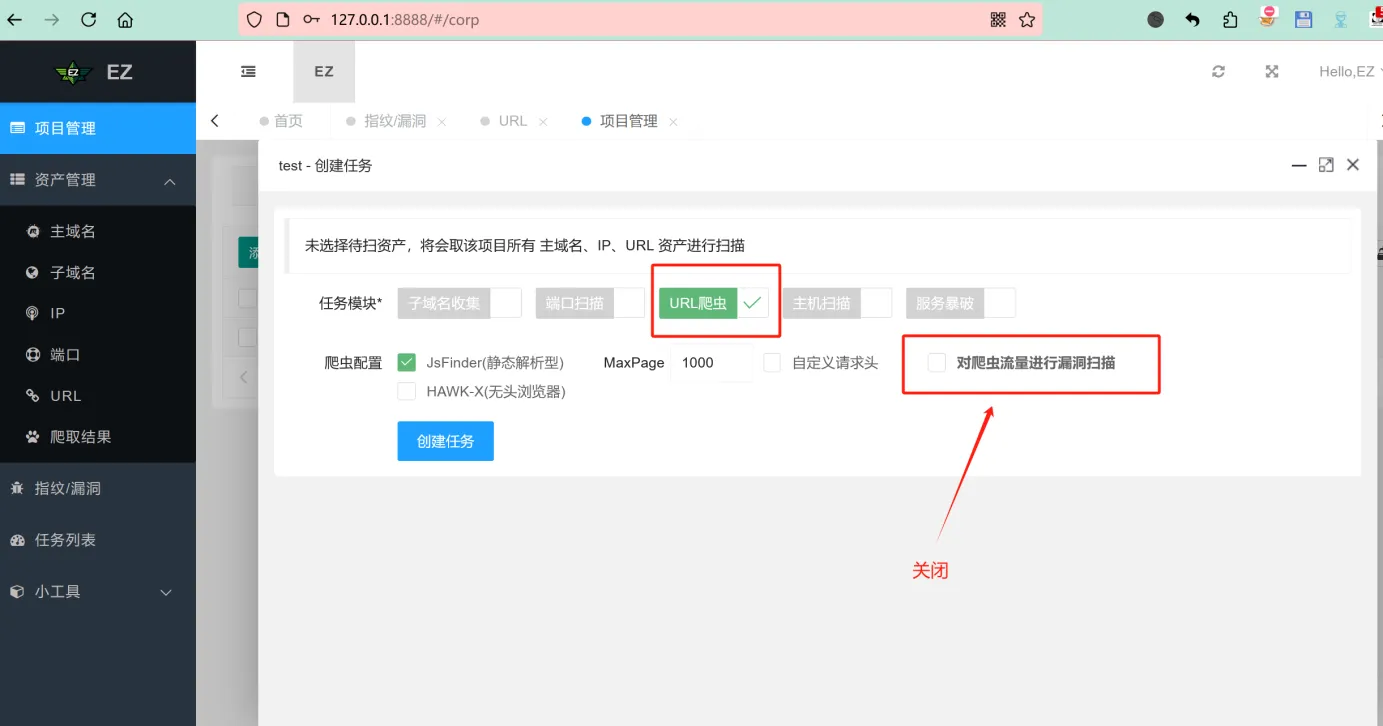
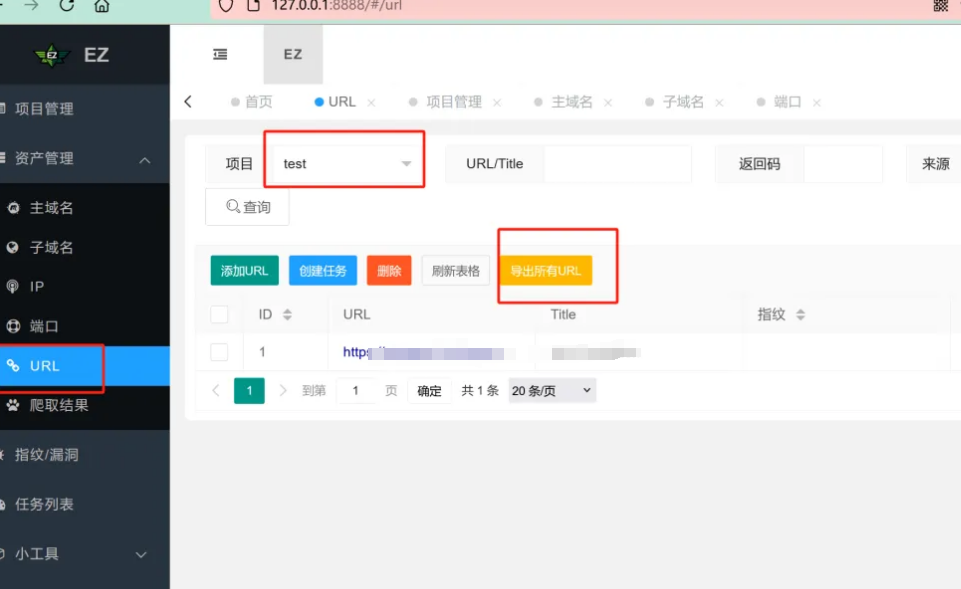
第4步:指纹识别
通过Finger、ehole对所有存活的非空URL进行WEB资产指纹识别
ARL、EZ会自动进行指纹识别有可能触发漏洞,无法避免
工具使用-Finger
使用方法
python Finger.py -f url.txt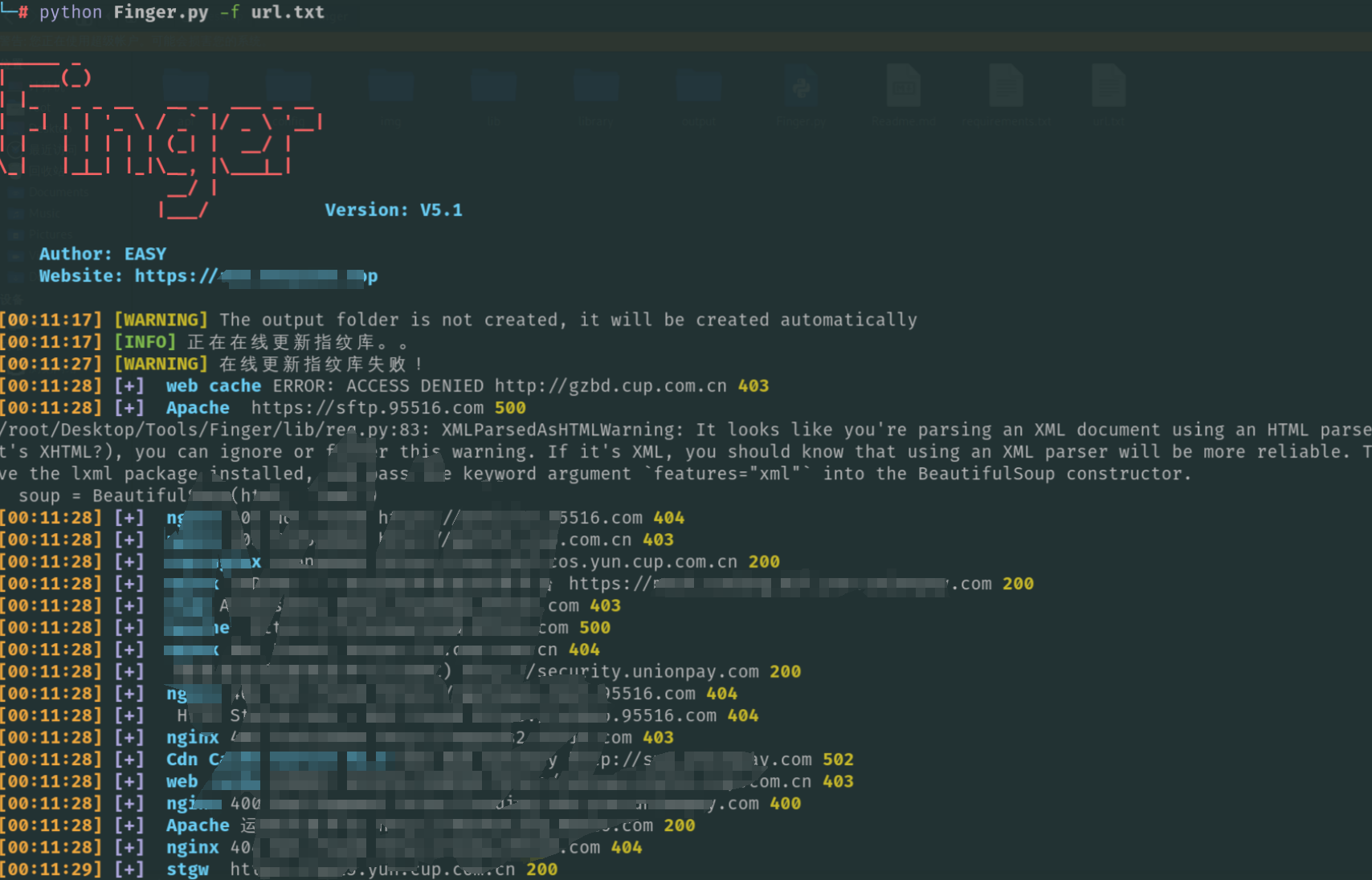
工具使用-ehole
EHole.exe -u url
Ehole3.0-Win.exe -l url.txt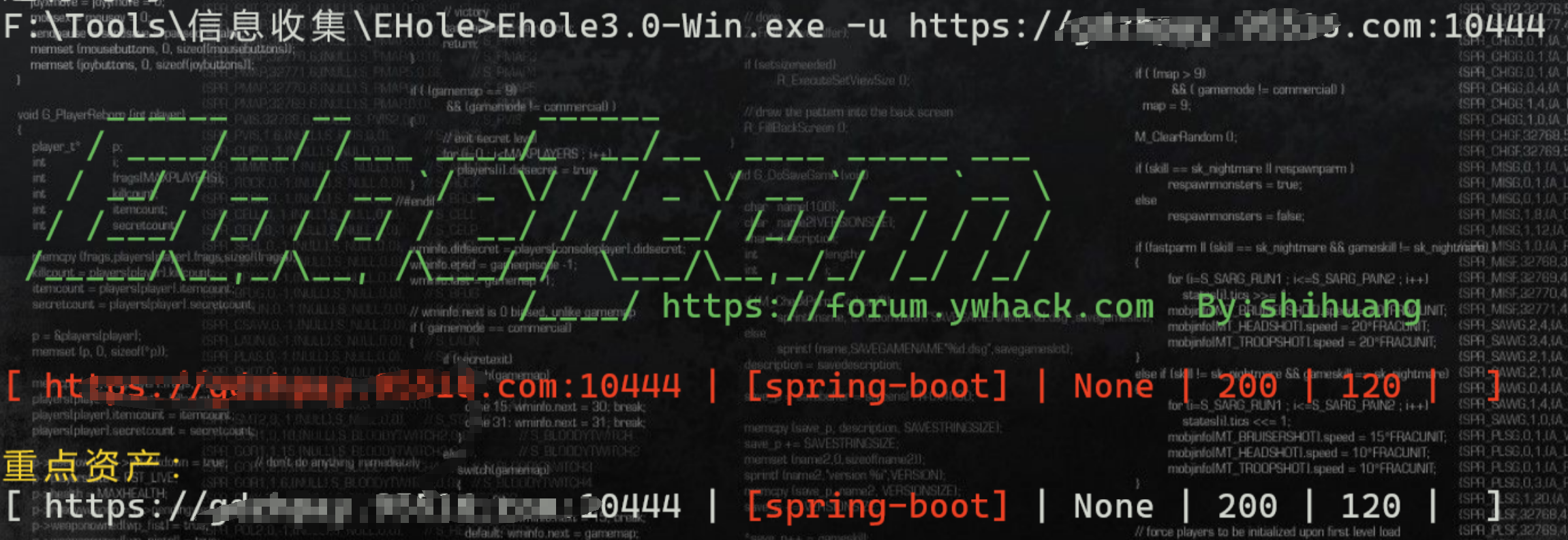
工具使用-gotoscan
gotoscan.exe -host https://xxx.com
gotoscan.exe -hosts url.txt第5步:JS文件探测、接口探测等
将URL中有WEB服务的资产去重后(可以针对content-length去重),进行JS文件探测、接口探测、路径探测等
对于404、403、401以及各种nginx、apache、IIS、spring等默认页面不要去重复,先爆路径,因为一个网站没有路由的时候,就都是这些默认页面内,这些页面可能长度都一样,如果此时还按照长度去重,有可能失去很多有价值的信息。
对于一些状态码是200的页面,这些页面有标题、有内容,返回长度较大、有健全的网站信息,这种一看就知道是真实站点的页面,可以进行去重。
由于后续会将有功能的站点进行JS扫描和手工测试等等,所以需要排除污染项(去重)
将404、403、401以及各种nginx、apache、IIS、spring等默认页面的资产进行路径探测,爆破找到入口路径后,也要进行JS文件探测、接口探测、路径探测等,目的是为了探测网站的敏感目录,接口泄露情况,未授权情况等
可以fuzz接口,可以嵌套fuzz路径
比如:某个发现某个URL的
/web目录是网站入口,还可以再对/web这个目录进行目录爆破
JS文件探测-工具使用-jjjjjjjjjjjjjs
该工具结合了URLFinder等,追求效率时可以只使用这个工具
使用方法
jjjjjjjjjjjjjs.exe url.txt pause
jjjjjjjjjjjjjs.exe url.txt fuzz nobody pause
jjjjjjjjjjjjjs.exe url.txt deep pause
该工具数据结果的可视化程度很差,需要做去重处理,然后对去重后的结果进行批量访问(找未授权比较高效)
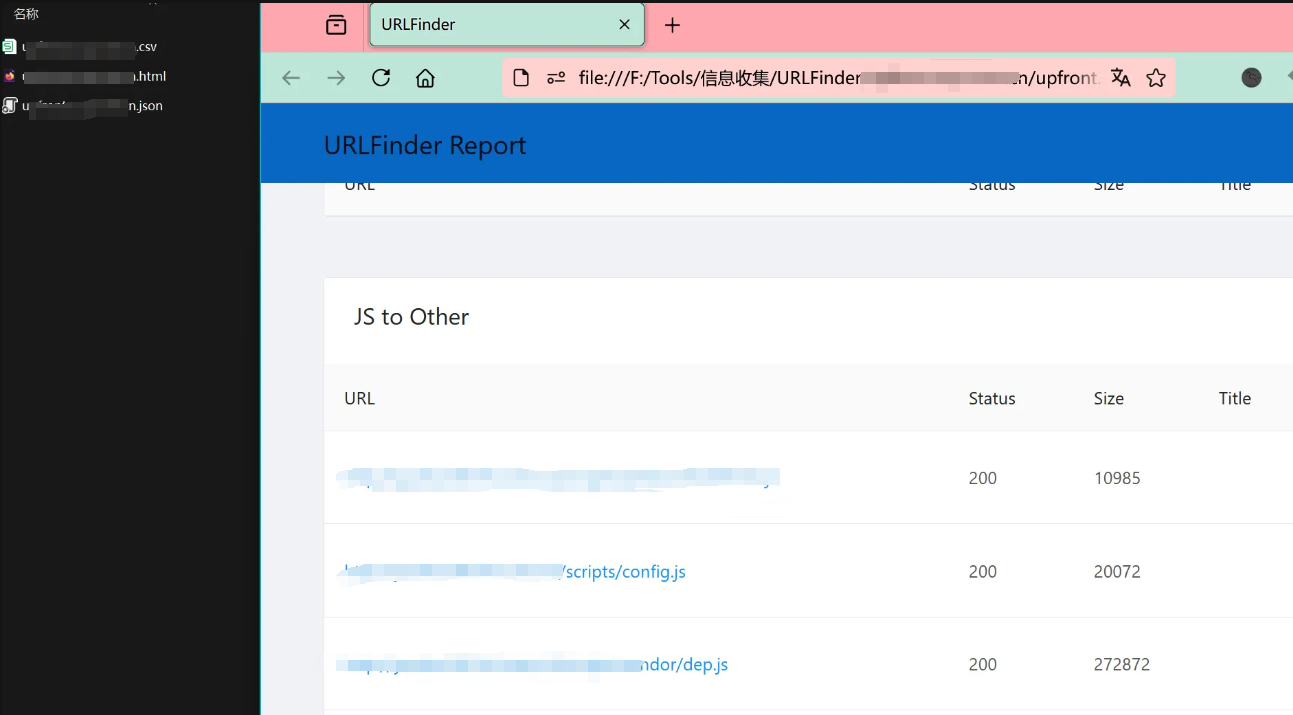
页面信息提取-工具使用-URLFinder
可快速发现和提取页面中的JS、URL和敏感信息
使用方法
URLFinder.exe -s all -m 3 -u URL
URLFinder.exe -s all -m 3 -f url.txt -o .
该工具输出结果的可视化效果比较好,但是效率较低
扫描完以后,会在工具所在目录生成一个文件夹,里面存有扫描结果
信息泄露检测-插件使用-Findsomthing
下载地址:https://github.com/momosecurity/FindSomething?tab=readme-ov-file
使用方法:导入火狐或者谷歌浏览器,访问站点时会自动爬取
路径爆破-工具使用-Dirsearch
python dirsearch.py -b yes -j yes -l url.txt -w dic.txt -x 405,400,403,429,401,404,501-599
-b yes: 这个选项可能是用来启用或禁用某种行为,具体取决于 dirsearch.py 的设计。根据DirSearch的文档,-b 通常用于启用备份文件扩展名扫描。
-j yes: 指定是否生成JSON格式的报告文件。
-l url.txt: 指定一个包含要扫描的目标URL列表的文本文件。
-w dic.txt: 指定一个字典文件,包含要尝试的路径和文件名。
-x 405,400,403,429,401,404,501-599: 指定一组HTTP状态码
python dirsearch.py -u url -i 200WEB路径暴力探测-工具使用-7kbscan(可导入自定义字典)
综合利用工具-无影v2.6
三、总结
目标单位-->发现域名-->资产测绘平台第一波信息收集-->将获取到的IP端口信息用于URL探测、指纹识别、服务识别-->获取到基于ip:port的应用指纹信息 以及基于URL的各种网页链接及其WEB指纹信息
主域名-->通过VPS或其他主机进行扫描获取目标子域名(oneforall、subfinder、arl、ez)
建议VPS或todesk远控其他主机进行该操作,第一轮是自己的物理机,很多操作可能导致已经被封IP了,所以第二轮通过另一个IP或者代理池,可以发现是否出现了被封IP的问题,这样能收集到更多可能因为被封IP而漏掉的指纹信息或者漏洞,将第一轮的结果进行漏洞利用时也建议使用VPS;
将VPS、 第三方主机的收集结果汇总去重复,然后进行新一轮自动化漏扫和手工渗透
使用物理机本机测试时,建议使用手机开启移动热点进行,不要使用家庭宽带用于渗透测试,实在担心被封建议用proxifier全局流量socks代理进行
关于代理方面的建议:非完全层面的全流量代理,大部分tcp确实能走全局,icmp无法代理;想要规避溯源风险的话可以通过虚拟机(仅主机模式)连接宿主机shadows socks服务端出网,但是效率较低,通常用于APT工作
四、补充:获取源码
body="web.config" && "oa" && "rar" && country="CN"
body="web.config" && "U8" && country="CN"
body="web.config" && "EAS" && country="CN"
body="web.config" && "k3s" && country="CN"
body="web.config" && "kingdee" && country="CN"
body="web.config" && "系统" && country="CN"
body="web.config" && "办公" && country="CN"
body="web.config" && "EKP" && country="CN"